Founded in 2013, the databricks data warehouse solution seeks to combine the functionality of multiple data storage structures geared towards data science, machine learning, and analytics. Drawing elements from data warehouses and data lakes, the Databricks platform introduces database analysts to its concept named “data lakehouse,” which is marketed as supporting “massive-scale data engineering, collaborative data science, full-lifecycle machine learning and business analytics.”
Data warehouses have been the prevalent approach to data storage for businesses with massive data sets and intelligence/analytics requirements. After being conceived in the 1980’s, and subsequently expanded through the development of MPP architectures (massively parallel processing), data warehouse service providers are rapidly evolving with competition from Amazon Redshift, Google BigQuery, Microsoft Azure Synapse and startups like Terradata and Snowflake.
However, data warehouses cannot support unstructured or semi-structured data. Thus, data lakes were created as a repository for raw data in a wide range of formats. These, too, bring with them several limitations – namely, they cannot support transactions or enforce data quality. This led to some organizations attempting to keep parallel data sets, having two different storage environments to service different needs, thus complexifying the entire data storage and retrieval process exponentially.
The Databricks Data Lakehouse platform is intended to be a collaborative solution for developers needing to bridge the gap between data lakes and data warehouses.
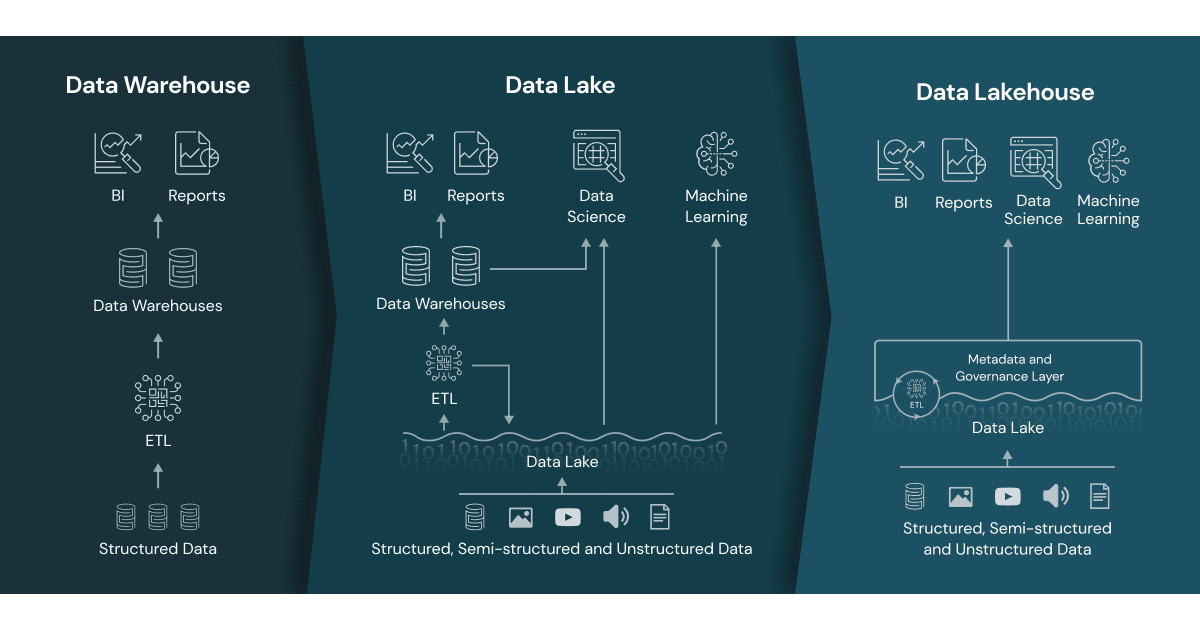
The Databricks lakehouse was created to address the limitations of both storage strategies. By combining many of the features of a data warehouse with low cost cloud storage formats (i.e. object stores), Databricks provides what is essentially a data warehouse for modern day systems.
The data lakehouse contains multiple pipelines which can read and write simultaneously as well as support ACID properties of database transactions (Atomicity, Consistency, Isolation, Durability). This ensures data integrity even as multiple users are reading and writing at the same time. With integral auditing and governance mechanisms, the lakehouse also supports schema enforcement for data warehouse architectures.
The Databricks platform also allows users to apply Business Intelligence tools directly to the stored data with no manipulation required. This is accomplished using open and standardized storage formats (Parquet is given as an example), accessed via API. This, coupled with the fact that the platform uses different clusters for storage and processing, reduces latency and improves scalability, both in terms of concurrent users and size of data.
Perhaps the greatest advantage of the Databricks platform is the diversity of data types and workloads it supports. Users can store, refine, and analyze images, video, audio, and semi-structured data. The variety of tools that can be given access to data stored in a lakehouse also makes a wide variety of workflows possible, including data science, machine learning, SQL queries and analytics. End to end streaming capabilities also mean that real-time reports can be generated from the lakehouse directly.
While the Databricks platform clearly offers many robust features, it may suffer from issues similar to many other Apache Spark-driven projects: complex deployments and large infrastructure overhead, which can lead to engineering resources being diverted from other high-priority tasks.
Overall, Databricks brings the data-minded development community a unique offering with a technical backend decades in the making. While Databricks isn’t a panacea for all storage needs, it seems to be well suited for a growing number of big-data applications.
As of its last venture capital financing round in August 2021, Databricks valuation is $38 billion, making it one of the highest value private software development companies. Many members of the databricks programming team came over from Apache Spark which also supports APIs in Java, Python, Scala, and R. Databricks currently works with over 5,000 organizations, including Comcast, AstraZeneca, HSBC, Starbucks, T-Mobile, Regeneron, and Shell.




